本文最后更新于:2024年3月23日 下午
Lab1的任务是要求实现一个reassembler,就是将乱序到来的字符串组装起来,再用lab0实现的bytestream有序读出。
标题stitch不是那只迪士尼的蓝色小考拉,是stitch的原意,缝,侧重于穿针引线的感觉。这个任务也是把一个个数据段(或许应该叫frame)穿起来。

在这个实验中,您将编写负责这种重组的数据结构:一个Reassembler。它将接收由字节字符串组成的子字符串,以及该字符串在流中的第一个字节的索引。流中的每个字节都有其自己唯一的索引,从零开始计数。一旦Reassembler知道流的下一个字节,它将将其写入ByteStream的Writer端。Reassembler的“客户”可以从同一ByteStream的Reader端读取。
具体地说,每次输入的形式如下
1
| void insert( uint64_t first_index, std::string data, bool is_last_substring );
|
每次输入index和string,我们需要将乱序到来的string排好序,尽快的输出。即,如果前面没有未到来的string,就将有序的string输出至上一节课实现的bytestream中。
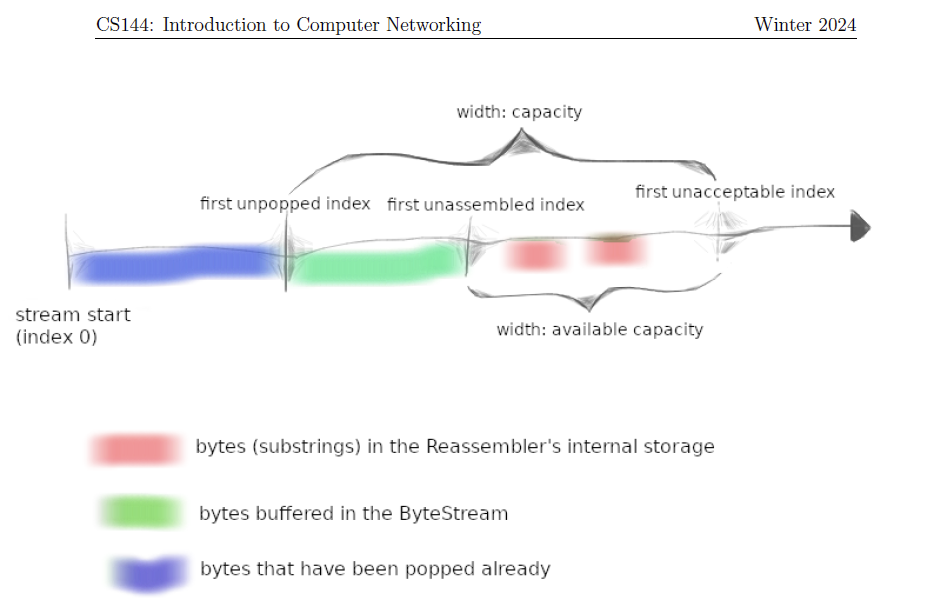
以该图为例,蓝色部分是已经被bytestream的reader端读取的数据,绿色是已经有序进入bytestream但是尚未读取的数据,红色是还不能进入bytestream因而被暂存的数据。
可以看到整个capacity是有限的,也就是说我们的reassembler占用的内存有上限,并且等于构造时传入的bytesteam的capacity。(构造函数使用了std::move的移动语义)。
所以在bytestream中未被读出的数据,和因为失序到达而被暂存在reassembler中的数据占用内存之和有上限。
首先,这意味着我们不能重复存储相同的数据,就是说,在数据出现重叠的时候只保存一份。
其次,first_unpoped_index和capacity决定了first_unacceptable_index,暂存更后面的数据是没有意义的。
(事实上这么做有可能有意义,这似乎取决于具体的TCP实现,但我们现在不需要这么做)
接下来我把QA和注释的翻译贴在这里。
- 因此,原则上,Reassembler将需要处理三类知识:
- 流中的下一个字节。一旦知道,Reassembler应该立即将它们推送到流(output.writer())中。
- 适合于流的可用容量但尚不能写入的字节,因为先前的字节仍未知。这些应该在Reassembler内部存储。
- 超出流可用容量的字节。这些应该被丢弃。Reassembler不会存储任何不能立即或者在先前的字节变为已知时立即推送到ByteStream中的字节。
- Q&A
- 我的实现应该有多高效?在这里,数据结构的选择再次很重要。请不要将其视为构建一个极度占用空间或时间效率低下的数据结构的挑战 - Reassembler将是您的TCP实现的基础。您有很多选择。
我们为您提供了一个基准;大于0.1 Gbit/s(每秒100兆位)的任何值都是可以接受的。顶级的Reassembler将达到10 Gbit/s。
- 应该如何处理不一致的子字符串?您可以假设它们不存在。也就是说,您可以假设有一个唯一的基础字节流,所有子字符串都是它的(准确的)切片。
- 我可以使用什么?您可以使用标准库的任何部分,只要您认为有帮助。特别是,我们希望您至少使用一种数据结构。
- 何时应该将字节写入流?尽快。唯一不应该在流中的情况是在它前面有一个尚未“推送”的字节时。
- 提供给insert()函数的子字符串可以重叠吗?可以。
- 我需要向Reassembler添加私有成员吗?是的。子字符串可以以任何顺序到达,因此您的数据结构将不得不“记住”子字符串,直到它们准备好放入流中 - 也就是说,直到它们之前的所有索引都已写入。
- 我们的重组数据结构是否可以存储重叠的子字符串?不行。可以实现一个“接口正确”的重组器来存储重叠的子字符串。但是允许重新组装器这样做会破坏“容量”作为内存限制的概念。如果调用者提供了关于相同索引的冗余信息,Reassembler应仅存储此信息的一个副本。
- 重新组装器是否会使用ByteStream的Reader端?不会 - 那是给外部客户的。Reassembler仅使用Writer端。
接下来让我们开始实现,我们需要添加哪些私有变量来记录呢?由图我们可以知道,要记录first_unpoped_index_和first_unassembled_index_;
要使用一个可以快速查找的数据结构暂存没有组装好的字符串,于是使用set。考虑is_last_substring的数据提前到达的可能性,我们要记录一下last。维护一个bytes_pending变量,实现获取暂存字符串长度。
最后,使用一个数据结构暂存字符串,因为要有序查找,使用了set。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| private:
ByteStream output_;
struct Seg {
uint64_t first_index;
std::string data;
bool operator< ( const Seg& other ) const {
return first_index < other.first_index;
}
Seg(uint64_t f, const std::string& d) : first_index(f), data(d) {};
};
std::set<Seg> segments_ {};
uint64_t bytes_waiting_ {};
uint64_t first_unpoped_index_ {};
uint64_t first_unassembled_index_ {};
uint64_t final_index_ = INT64_MAX;
|
接下来,我们朴素的想法就是,保证set中的分段不重叠,接下来当插入一个新的子串时,只会出现以下的情况:
和起点在它之前的子串重合。此时删除新串的重合部分即可。需要注意的是,最多只有一个旧的子串满足这种情况,因为set中的子串是互相不重叠的。
和起点在它之后的字串重合(但不覆盖)此时删除新串的重合部分即可。需要注意的是,最多只有一个旧的子串满足这种情况,因为set中的子串是互相不重叠的。
覆盖起点在它之后的字串。此时删除旧串即可,可能有若干个旧字串满足这种情况。
在处理好之后就可以将其插入set。
于是,我们需要利用set的特性,用lower_bound查找,可以快速找到第一个起点大于等于它的字串,之后将其向前单步迭代就是情况1的可能 , 将其向后一直迭代即可确定情况2和情况3。
接下来,我们在插入之后立刻check能否向前推进first_unassembled_index_即可。
Note:在处理情况3和check过程中,我们会对迭代器指向的元素进行删除,此时需要谨慎处理。
完整代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| void Reassembler::insert( uint64_t first_index, string data, bool is_last_substring )
{
uint64_t last_index = first_index + data.size();
uint64_t first_unacceptable = first_unassembled_index_ + output_.writer().available_capacity();
if ( is_last_substring ) {
final_index_ = last_index;
}
if ( first_index < first_unassembled_index_ ) {
if ( first_index + data.size() <= first_unassembled_index_ ) {
check_push();
return;
} else {
data.erase( 0, first_unassembled_index_ - first_index );
first_index = first_unassembled_index_;
}
}
if ( first_unacceptable <= first_index ) {
return;
}
if ( last_index > first_unacceptable ) {
data.erase( first_unacceptable - first_index );
}
if ( !segments_.empty() ) {
auto cur = segments_.lower_bound( Seg( first_index, "" ) );
if ( cur != segments_.begin() ) {
cur--;
if ( cur->first_index + cur->data.size() > first_index ) {
data.erase( 0, cur->first_index + cur->data.size() - first_index );
first_index += cur->first_index + cur->data.size() - first_index;
}
}
cur = segments_.lower_bound( Seg( first_index, "" ) );
while ( cur != segments_.end() && cur->first_index < last_index ) {
if ( cur->first_index + cur->data.size() <= last_index ) {
bytes_waiting_ -= cur->data.size();
segments_.erase( cur );
cur = segments_.lower_bound( Seg( first_index, "" ) );
} else {
data.erase( cur->first_index - first_index);
break;
}
}
}
segments_.insert( Seg( first_index, data ) );
bytes_waiting_ += data.size();
check_push();
}
uint64_t Reassembler::bytes_pending() const
{
return bytes_waiting_;
}
void Reassembler::check_push() {
while ( !segments_.empty() ) {
auto seg = segments_.begin();
if ( seg->first_index == first_unassembled_index_ ) {
output_.writer().push( seg->data );
auto tmp = seg;
first_unassembled_index_ += seg->data.size();
bytes_waiting_ -= seg->data.size();
segments_.erase(tmp);
if ( first_unassembled_index_ >= final_index_ ) {
output_.writer().close();
}
} else {
break;
}
}
}
|