CS144-check4
本文最后更新于:2024年3月23日 晚上
奖励关,前面不出错的话不需要写什么代码,简单分析一下数据就可以了。
总览
到目前为止,在这门课程中,你已经以几乎完全符合标准的方式实现了传输控制协议(TCP)。可以说,TCP实现是世界上最流行的计算机程序,存在于数十亿设备中。大多数实现使用的策略与你的不同,但由于所有TCP实现共享一种通用语言,它们都是互操作的——每个TCP实现都可以与任何其他实现作为对等体。这个检查点是关于在现实世界中测试你的TCP实现,并测量特定互联网路径的长期统计数据。
如果你的TCP实现编写得当,你可能不需要为这个检查点编写任何代码。但尽管我们已经尽力了,仍有可能有错误未被我们的单元测试发现。如果你发现问题,你可能会想使用wireshark进行调试并修复任何错误。我们欢迎(并奖励!)你为TCP模块贡献的任何测试用例,以捕获现有单元测试未能捕获的错误。
收集数据
在互联网上选择一个远程主机,该主机的往返时间(RTT)(从您的虚拟机出发)至少为100毫秒。一些可能的选择包括:
- www.cs.ox.ac.uk (英国牛津大学计算机科学系服务器)
- 162.105.253.58 (中国北京大学计算机中心)
- www.canterbury.ac.nz (新西兰坎特伯雷大学服务器)
- 41.186.255.86 (卢旺达MTN)
首选:从您的位置到达的RTT至少为100毫秒的选择
使用mtr或traceroute命令追踪您的虚拟机与该主机之间的路由。
运行ping命令至少两小时,以收集有关此互联网路径的数据。使用像ping -D -n -i 0.2 主机名 | tee data.txt这样的命令来保存数据到“data.txt”文件中。(-D参数使ping记录每一行的时间戳,-i 0.2使其每0.2秒发送一个“回声请求”ICMP消息。-n参数使其跳过尝试使用DNS反向查找回复IP地址到主机名。)
注意:每0.2秒发送一个默认大小的ping是可以的,但请不要以比这更快的速度发送大量流量。
Answer
我的测试是使用校园网直连的的41.186.255.86
- 整个时间间隔的总体送达率是多少?换句话说:收到的回声回复数量除以发送的回声请求数量是多少?(注意:GNU/Linux上的ping不会打印未收到的回声回复的任何消息。你需要通过查找缺失的序列号来识别缺失的回复。)
- 总发送: 36052
丢包: 803
送达率: 0.9777266171086209
- 最长的连续成功ping(连续回复)字符串是多长?
- 最长连续成功: 537
- 最长的连续丢失(连续未回复)序列是多长?
- 最长连续丢包: 2
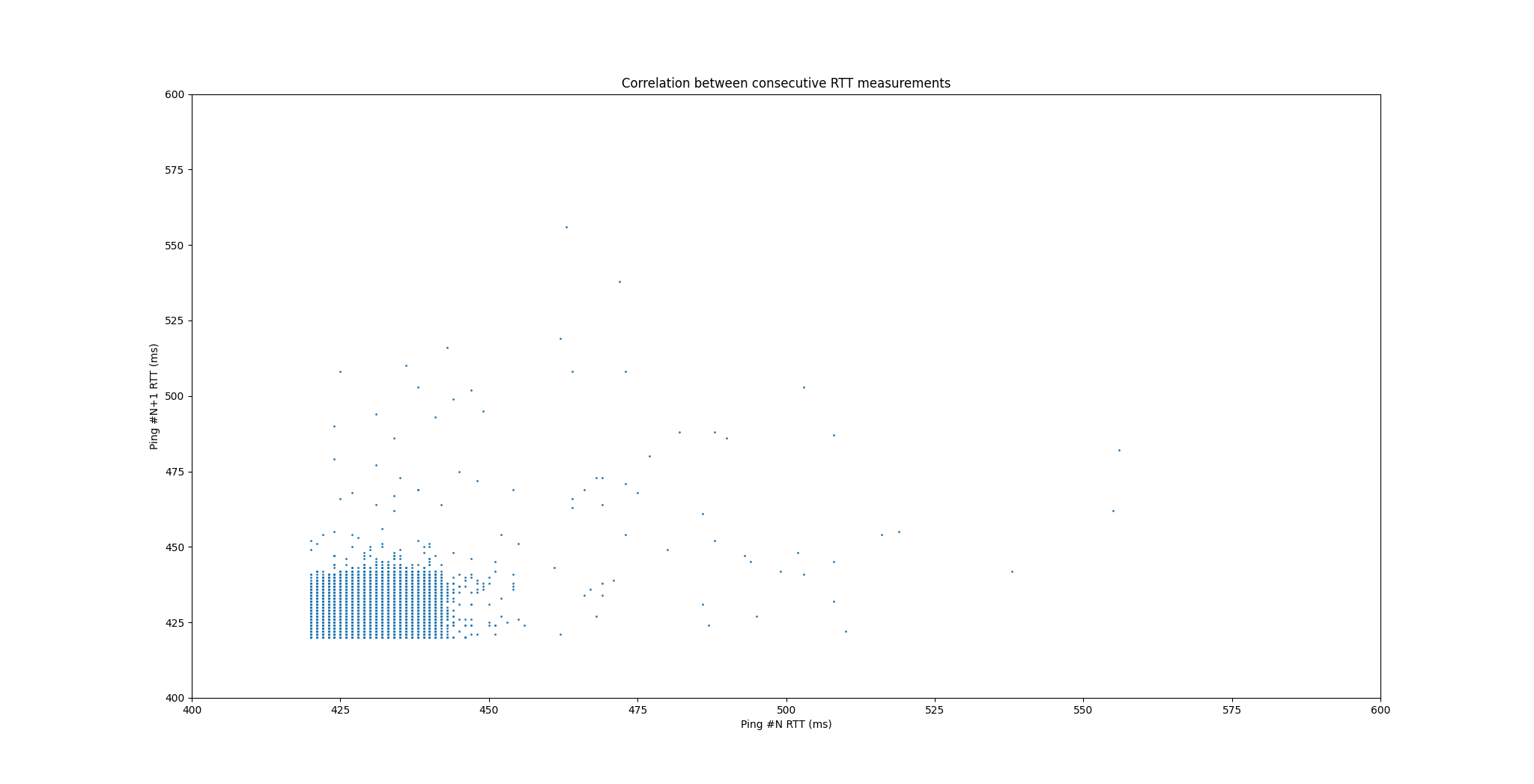
- “数据包丢失”事件随时间的独立性或相关性如何?换句话说:
给定回声请求#N收到了回复,回声请求#(N+1)也成功回复的概率是多少?
给定回声请求#N未收到回复,回声请求#(N+1)成功回复的概率是多少?
这些数字(条件送达率)与第一个问题中的总体“无条件”包送达率相比如何?丢失是独立的还是成串的?
- 总体送达率: 0.97773
给定回声请求#N收到了回复,回声请求#(N+1)也成功回复的概率: 0.97773
给定回声请求#N未收到回复,回声请求#(N+1)成功回复的概率: 0.97758
丢失可以认为是独立的,但独立和成串并不显著。
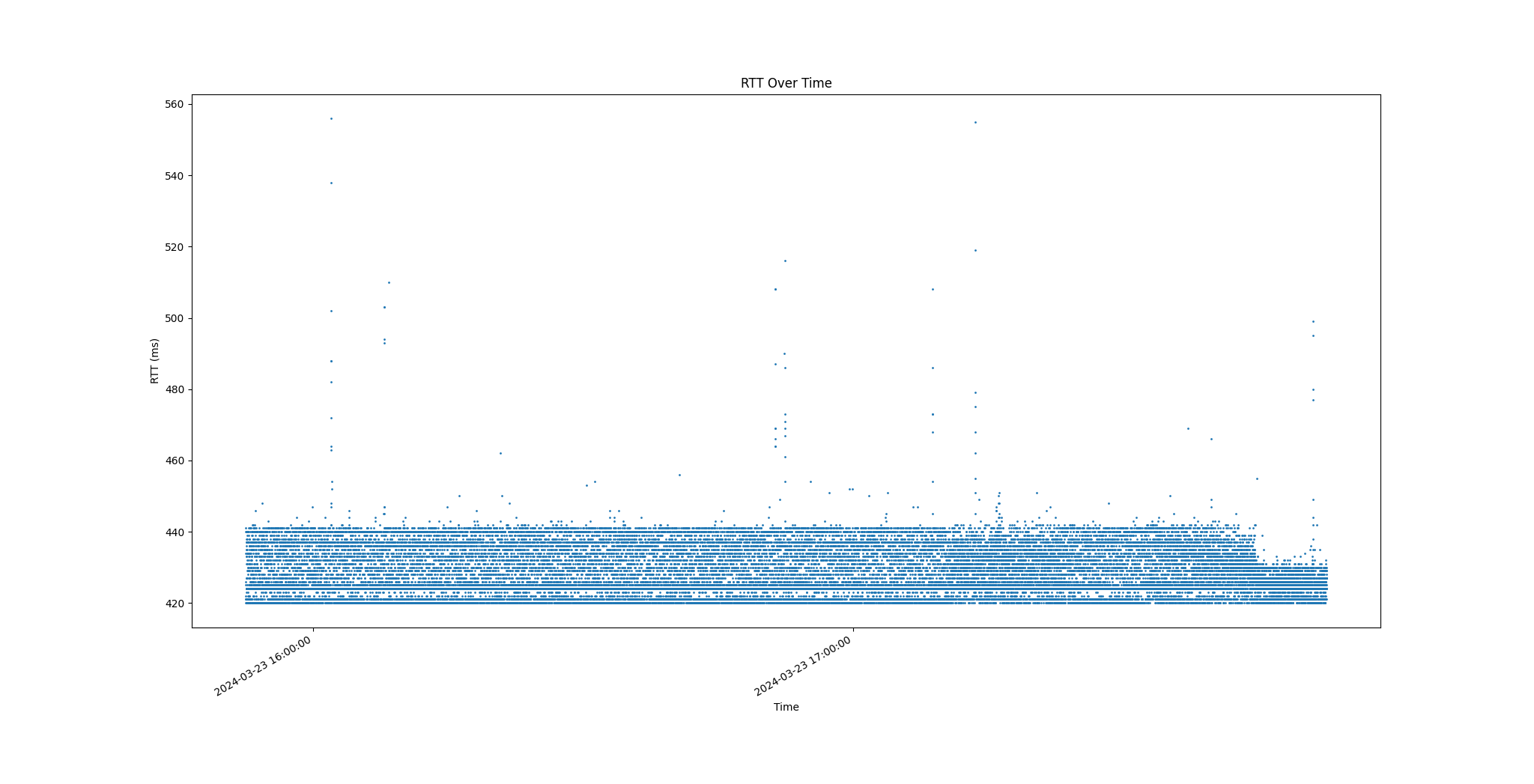
- 整个时间间隔内看到的最小RTT是多少?(这可能是真实MinRTT的合理近似……)
- RTT的最小值: 420
- 整个时间间隔内看到的最大RTT是多少?
- RTT的最大值: 556
- 制作RTT作为时间函数的图表。x轴用实际时间标记(覆盖2小时以上的时间段),y轴应该是RTT的毫秒数。
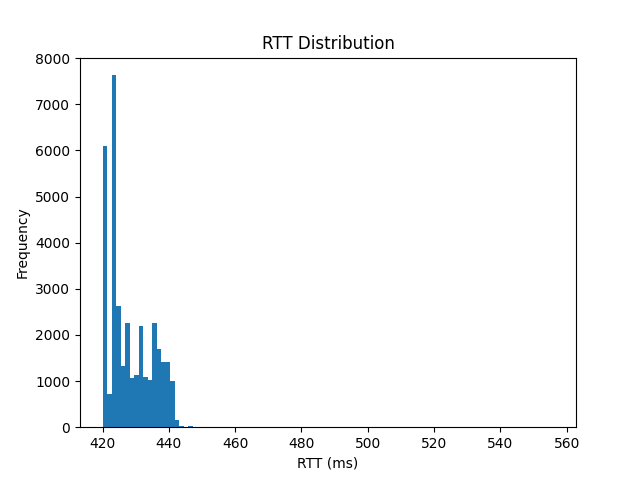
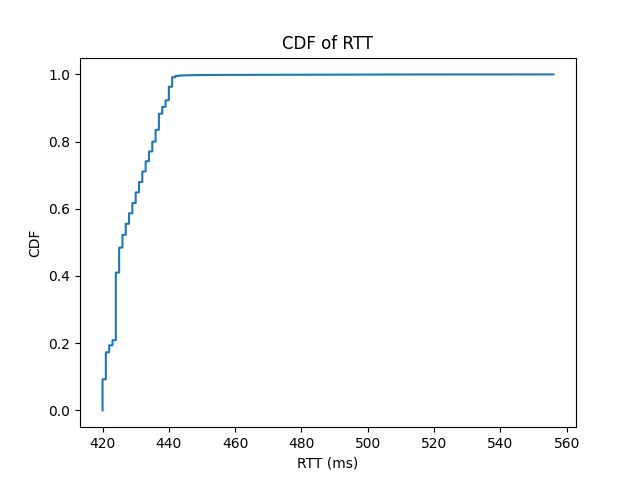
- 制作观察到的RTT分布的直方图或累积分布函数。分布的大致形状是什么?
- 制作“ping #N的RTT”和“ping #N+1的RTT”之间的相关性图。x轴应该是第一个RTT的毫秒数,y轴应该是第二个RTT的毫秒数。RTT随时间的相关性如何?
- 从数据中得出什么结论?网络路径的行为是否符合你的预期?查看图表和摘要统计数据有什么(如果有的话)让你感到惊讶的地方?
- 似乎看起来在足够正常的网络环境下,网络请求可以视为独立的,相邻请求之间的延迟和丢包都没有什么相关性。或许是因为在我测的时候网络相当正常,或者是网络拥有足够快的修复能力(?
如果你也做了的话再评论区里讨论一下吧
Code
另附源代码
1 | |